当AI学会“横向生长”——走近宽度学习系统
走进一家大型工厂的生产线,你会看到高速运转的传送带、精准分拣的机械臂,以及一双“无形的眼睛”——摄像头。它们实时捕捉每一件产品的细节,判断是否合格。类似的场景在我们的生活中比比皆是:手机刷脸解锁、地铁闸机人脸识别、商场摄像头客流分析等。这些应用的共同点是——它们必须又快又准:慢一秒,体验就打折扣;识别不准,更可能带来安全风险或经济损失。因此,在这些高效运转的智能场景背后,藏着人工智能快速而准确处理信息的秘密。
今天,带大家认识一种不走寻常路的人工智能方法——宽度学习系统(Broad Learning System,BLS)。

效率与灵活性之选:“纵向”VS“横向”
在人工智能的主流道路上,深度学习一直是领跑者。它通过一层层堆叠神经网络,让模型的特征提取能力越来越强。但深度并非没有代价:训练需要大量数据、算力和时间,一旦有新任务或新数据,往往需要重新训练整个模型,这在实时性要求高的应用中显得笨重。

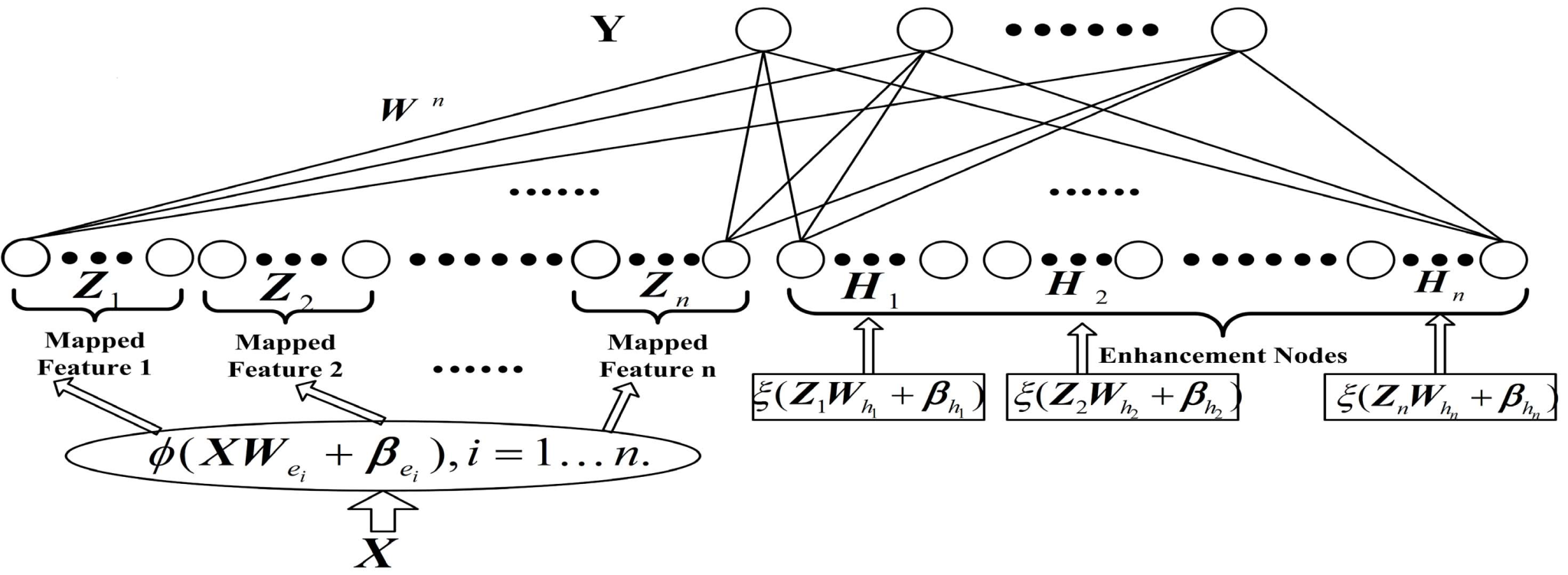
宽度学习系统选择了一条不同的路径——不纵向深入,而是横向扩展。它在同一层网络结构里,平行地建立多个特征映射和增强节点,就像在一条高速公路上增加多条车道,让信息同时并行处理。更重要的是,其学习过程非常高效:接收输入数据后,先通过特征层得到映射特征,再计算增强层的输出,并将这两部分特征合并成一个矩阵;通过计算这个矩阵的广义逆,就能一步求出输出层的权重。由于训练不依赖反复迭代的反向传播,宽度学习的建模时间大幅缩短。
《Broad Learning System: An Effective and Efficient
Incremental Learning System Without
the Need for Deep Architecture》
增量学习:为AI快速升级
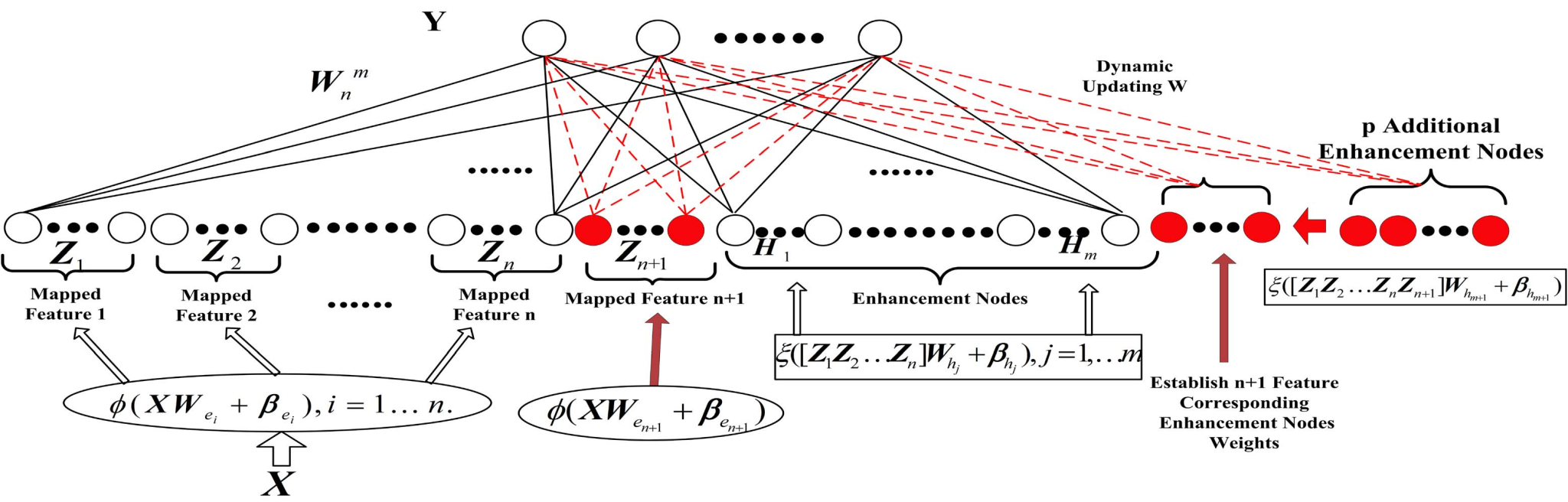
宽度学习还有一个深度学习不擅长的能力——增量学习。想象一个工业质检系统,运行几个月后发现了新的缺陷类型。传统深度网络可能需要重新收集数据、重新训练整个模型;而宽度学习可以在原有的模型结构上直接增加新的特征节点或增强节点,用增量矩阵更新的方法快速“学会”识别这种缺陷。
再举个生活中的例子:假设我们训练了一个识别“猫” 的宽度学习系统,它已经能通过 “尖耳朵”“长尾巴” 等特征做出判断。如果现在要让它同时识别 “狗”,不需要重新训练整个模型,只需在特征层加入 “耷拉的耳朵”“短尾巴” 等新特征,增强层会自动把新旧特征组合(比如 “尖耳朵+短尾巴”是猫、“耷拉耳朵+长尾巴”是狗),输出层就能同时区分猫和狗了。这种特性让它在在线学习、流数据分析、边缘计算等场景下尤其高效。

实力验证:宽度学习的性能优势
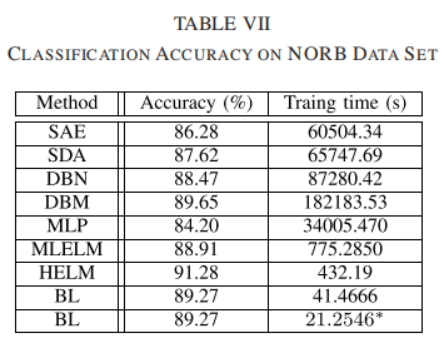
为了验证宽度学习的性能,研究人员进行了一系列的分类和回归实验。在UCI机器学习数据库中的十余个回归任务上,宽度学习在训练时间更少的情况下,与传统方法相比仍然具有更低的均方根误差;在手写数字识别(MNIST)、目标识别(NORB)、人脸识别(MS-CELEB-1M)和图像分类(CIFAR10/100)等视觉任务中,宽度学习的训练时间比最先进的深度学习方法快了3个数量级以上,而准确率相差无几甚至更优。这意味着,在一些实时性优先的任务里,BLS可以用更低的计算代价提供接近深度网络的性能。
不止高效:AI发展路径的思考
宽度学习打破了“深度才是唯一答案”的思维定势。它让我们看到,人工智能的效率、适应性和可扩展性同样重要。在资源受限的设备上,它能让AI真正落地;在快速变化的业务场景里,它能缩短模型适应新环境的周期;在理论研究上,它也为理解神经网络的本质提供了新的切入点。宽度学习系统提醒我们,人工智能的发展并非单行道,多样化的技术路线,才可能让AI真正走得更远。
作者:胡筱曼、雷春雨、刘竹琳
声明:本公众号发布的部分图文素材等来源于第三方或网络信息,本文仅用于公益科普,版权归原作者或机构所有,内容如有侵权,请及时联系本公众号删除。本文中来源于文献的素材均引自
http://ieeexplore.ieee.org/document/7987745