会议预告:CSIG-广东省CVPR 2021论文预交流在线学术报告会

主办: 中国图象图形学学会(CSIG)
琶洲实验室
承办:广东省图像图形学会(GDSIG)
CSIG-文档图像分析与识别专委会
CSIG-机器视觉专委会
GDSIG-计算机视觉专委会
直播技术支持:极市平台
国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)是IEEE一年一度的学术性权威会议,是世界顶级计算机视觉会议之一。CVPR会议的主要内容涵盖计算机视觉、模式识别、图像处理、人工智能等各方面前沿技术。目前,在中国计算机学会推荐国际学术会议的排名中,CVPR为人工智能领域的A类会议。在Google学术指标(Google Scholar Metrics) 计算机视觉及模式识别类别中,CVPR排名第一。
为了给本领域研究者、技术开发人员和研究生介绍计算机视觉部分前沿理论方法和最新进展,我们邀请了13位广东省在此领域部分优秀团队的青年学子,介绍他们今年被CVPR 2021录用论文的研究成果。
CSIG-广东省CVPR 2021论文预交流学术报告会定于2021年5月8日(星期六)在线举办。相关信息如下:
时间:2021年5月8日 星期六
会议直播网址: http://live.bilibili.com/3344545
参与提问及讨论:进入上述直播网站,可以用弹幕等打字方式提问。
会议日程一览表:
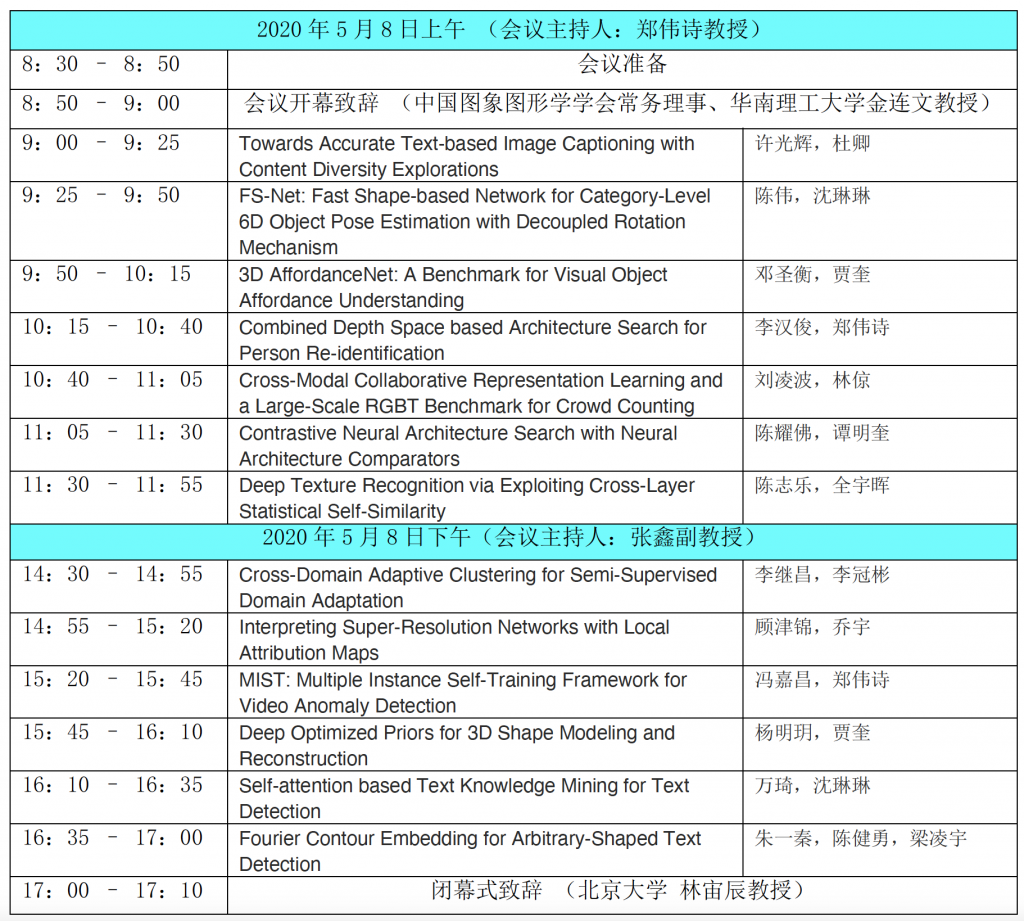
*备注:每篇论文由排序第一的报告人进行演讲报告,其余报告人协助回答问题及参与讨论。
报名注册:
- 本次在线会议免费参加,不收取任何注册费。
- 普通听众请通过直播网址参加会议。
- 特邀讲者及嘉宾可通过腾讯会议系统参加现场讨论,会议ID另行通知。
联系人:
郑老师, Email: zhwshi@mail.sysu.edu.cn
张老师, Email: eexinzhang@scut.edu.cn
报告摘要:
报告1. Towards Accurate Text-based Image Captioning with Content Diversity Explorations
摘要:Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct the multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
论文链接:https://tanmingkui.github.io/files/publications/Towards_Accurate_Text-based.pdf
代码链接:https://github.com/guanghuixu/AnchorCaptioner
报告2. Interpreting Super-Resolution Networks with Local Attribution Maps
摘要:Image super-resolution (SR) techniques have been developing rapidly, benefiting from the invention of deep networks and its successive breakthroughs. However, it is acknowledged that deep learning and deep neural networks are difficult to interpret. SR networks inherit this mysterious nature and little works make attempt to understand them. In this paper, we perform attribution analysis of SR networks, which aims at finding the input pixels that strongly influence the SR results. We propose a novel attribution approach called local attribution map (LAM), which inherits the integral gradient method yet with two unique features. One is to use the blurred image as the baseline input, and the other is to adopt the progressive blurring function as the path function. Based on LAM, we show that:(1) SR networks with a wider range of involved input pixels could achieve better performance.(2) Attention networks and non-local networks extract features from a wider range of input pixels.(3) Comparing with the range that actually contributes, the receptive field is large enough for most deep networks.(4) For SR networks, textures with regular stripes or grids are more likely to be noticed, while complex semantics are difficult to utilize. Our work opens new directions for designing SR networks and interpreting low-level vision deep models.
论文链接:https://arxiv.org/pdf/2011.11036
代码链接:https://x-lowlevel-vision.github.io/lam.html
报告3. 3D AffordanceNet: A Benchmark for Visual Object Affordance Understanding
摘要:The ability to understand the ways to interact with objects from visual cues, a.k.a. visual affordance, is essential to vision-guided robotic research. This involves categorizing, segmenting and reasoning of visual affordance. Relevant studies in 2D and 2.5D image domains have been made previously, however, a truly functional understanding of object affordance requires learning and prediction in the 3D physical domain, which is still absent in the community. In this work, we present a 3D AffordanceNet dataset, a benchmark of 23k shapes from 23 semantic object categories, annotated with 18 visual affordance categories. Based on this dataset, we provide three benchmarking tasks for evaluating visual affordance understanding, including full-shape, partial-view and rotation-invariant affordance estimations. Three state-of-the-art point cloud deep learning networks are evaluated on all tasks. In addition we also investigate a semi-supervised learning setup to explore the possibility to benefit from unlabeled data. Comprehensive results on our contributed dataset show the promise of visual affordance understanding as a valuable yet challenging benchmark.
论文链接:https://arxiv.org/abs/2103.16397
代码链接:https://github.com/Gorilla-Lab-SCUT/AffordanceNet
报告4. Combined Depth Space based Architecture Search for Person Re-identification
摘要:Most works on person re-identification (ReID) take advantage of large backbone networks such as ResNet, which are designed for image classification instead of ReID, for feature extraction. However, these backbones may not be computationally efficient or the most suitable architectures for ReID. In this work, we aim to design a lightweight and suitable network for ReID. We propose a novel search space called Combined Depth Space (CDS), based on which we search for an efficient network architecture, which we call CDNet, via a differentiable architecture search algorithm. Through the use of the combined basic building blocks in CDS, CDNet tends to focus on combined pattern information that is typically found in images of pedestrians. We then propose a low-cost search strategy named the Top-k Sample Search strategy to make full use of the search space and avoid trapping in local optimal result. Furthermore, an effective Fine-grained Balance Neck (FBLNeck), which is removable at the inference time, is presented to balance the effects of triplet loss and softmax loss during the training process. Extensive experiments show that our CDNet (~1.8M parameters) has comparable performance with state-of-the-art lightweight networks.
论文链接:https://arxiv.org/abs/2104.04163
代码链接:
报告5. Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
摘要:Crowd counting is a fundamental yet challenging task, which desires rich information to generate pixel-wise crowd density maps. However, most previous methods only used the limited information of RGB images and cannot well discover potential pedestrians in unconstrained scenarios. In this work, we find that incorporating optical and thermal information can greatly help to recognize pedestrians. To promote future researches in this field, we introduce a large-scale RGBT Crowd Counting (RGBT-CC) benchmark, which contains 2,030 pairs of RGB-thermal images with 138,389 annotated people. Furthermore, to facilitate the multimodal crowd counting, we propose a cross-modal collaborative representation learning framework, which consists of multiple modality-specific branches, a modality-shared branch, and an Information Aggregation-Distribution Module (IADM) to capture the complementary information of different modalities fully. Specifically, our IADM incorporates two collaborative information transfers to dynamically enhance the modality-shared and modality-specific representations with a dual information propagation mechanism. Extensive experiments conducted on the RGBT-CC benchmark demonstrate the effectiveness of our framework for RGBT crowd counting. Moreover, the proposed approach is universal for multimodal crowd counting and is also capable to achieve superior performance on the ShanghaiTechRGBD dataset. Finally, our source code and benchmark are released at http://lingboliu.com/RGBT_Crowd_Counting.html.
论文链接:https://arxiv.org/abs/2012.04529
代码链接:http://lingboliu.com/RGBT_Crowd_Counting.html
报告6. Contrastive Neural Architecture Search with Neural Architecture Comparators
摘要:One of the key steps in Neural Architecture Search (NAS) is to estimate the performance of candidate architectures. Existing methods either directly use the validation performance or learn a predictor to estimate the performance. However, these methods can be either computationally expensive or very inaccurate, which may severely affect the search efficiency and performance. Moreover, as it is very difficult to annotate architectures with accurate performance on specific tasks, learning a promising performance predictor is often non-trivial due to the lack of labeled data. In this paper, we argue that it may not be necessary to estimate the absolute performance for NAS. On the contrary, we may need only to understand whether an architecture is better than a baseline one. However, how to exploit this comparison information as the reward and how to well use the limited labeled data remains two great challenges. In this paper, we propose a novel Contrastive Neural Architecture Search (CTNAS) method which performs architecture search by taking the comparison results between architectures as the reward. Specifically, we design and learn a Neural Architecture Comparator (NAC) to compute the probability of candidate architectures being better than a baseline one. Moreover, we present a baseline updating scheme to improve the baseline iteratively in a curriculum learning manner. More critically, we theoretically show that learning NAC is equivalent to optimizing the ranking over architectures. Extensive experiments in three search spaces demonstrate the superiority of our CTNAS over existing methods.
论文链接:https://arxiv.org/abs/2103.05471
代码链接:https://github.com/chenyaofo/CTNAS
报告7. Deep Texture Recognition via Exploiting Cross-Layer Statistical Self-Similarity
摘要:In recent years, convolutional neural networks (CNNs) have become a prominent tool for texture recognition. The key of existing CNN-based approaches is aggregating the convolutional features into a robust yet discriminative description. This paper presents a novel feature aggregation module called CLASS (Cross-Layer Aggregation of Statistical Self-similarity) for texture recognition. We model the CNN feature maps across different layers, as a dynamic process which carries the statistical self-similarity (SSS), one well-known property of texture, from input image along the network depth dimension. The CLASS module characterizes the cross-layer SSS using a soft histogram of local differential box-counting dimensions of cross-layer features. The resulting descriptor encodes both cross-layer dynamics and local SSS of input image, providing additional discrimination over the often-used global average pooling. Integrating CLASS into a ResNet backbone, we develop CLASSNet, an effective deep model for texture recognition, which shows state-of-the-art performance in the experiments.
报告8. Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation
摘要:In semi-supervised domain adaptation, a few labeled samples per class in the target domain guide features of the remaining target samples to aggregate around them. However, the trained model cannot produce a highly discriminative feature representation for the target domain because the training data is dominated by labeled samples from the source domain. This could lead to disconnection between the labeled and unlabeled target samples as well as misalignment between unlabeled target samples and the source domain. In this paper, we propose a novel approach called Cross-domain Adaptive Clustering to address this problem. To achieve both inter-domain and intra-domain adaptation, we first introduce an adversarial adaptive clustering loss to group features of unlabeled target data into clusters and perform cluster-wise feature alignment across the source and target domains. We further apply pseudo labeling to unlabeled samples in the target domain and retain pseudo-labels with high confidence. Pseudo labeling expands the number of “labeled” samples in each class in the target domain, and thus produces a more robust and powerful cluster core for each class to facilitate adversarial learning. Extensive experiments on benchmark datasets, including DomainNet, Office-Home and Office, demonstrate that our proposed approach achieves the state-of-the-art performance in semi-supervised domain adaptation.
论文链接:https://arxiv.org/abs/2104.09415v1
代码链接:https://github.com/lijichang/CVPR2021-SSDA
报告9. FS-Net: Fast Shape-based Network for Category-Level 6D Object Pose Estimation with Decoupled Rotation Mechanism
摘要:In this paper, we focus on category-level 6D pose and size estimation from a monocular RGB-D image. Previous methods suffer from inefficient category-level pose feature extraction, which leads to low accuracy and inference speed. To tackle this problem, we propose a fast shape-based network (FS-Net) with efficient category-level feature extraction for 6D pose estimation. First, we design an orientation aware autoencoder with 3D graph convolution for latent feature extraction. Thanks to the shift and scale-invariance properties of 3D graph convolution, the learned latent feature is insensitive to point shift and object size. Then, to efficiently decode category-level rotation information from the latent feature, we propose a novel decoupled rotation mechanism that employs two decoders to complementarily access the rotation information. For translation and size, we estimate them by two residuals: the difference between the mean of object points and ground truth translation, and the difference between the mean size of the category and ground truth size, respectively. Finally, to increase the generalization ability of the FS-Net, we propose an online box-cage based 3D deformation mechanism to augment the training data. Extensive experiments on two benchmark datasets show that the proposed method achieves state-of-the-art performance in both category- and instance-level 6D object pose estimation. Especially in category-level pose estimation, without extra synthetic data, our method outperforms existing methods by 6.3% on the NOCS-REAL dataset.
论文链接:http://arxiv.org/abs/2103.07054
代码链接:https://github.com/DC1991/FS-Net
报告10. MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection
摘要:Weakly supervised video anomaly detection (WS-VAD) is to distinguish anomalies from normal events based on discriminative representations. Most existing works are limited in insufficient video representations. In this work, we develop a multiple instance self-training framework (MIST)to efficiently refine task-specific discriminative representations with only video-level annotations. In particular, MIST is composed of 1) a multiple instance pseudo label generator, which adapts a sparse continuous sampling strategy to produce more reliable clip-level pseudo labels, and 2) a self-guided attention boosted feature encoder that aims to automatically focus on anomalous regions in frames while extracting task-specific representations. Moreover, we adopt a self-training scheme to optimize both components and finally obtain a task-specific feature encoder. Extensive experiments on two public datasets demonstrate the efficacy of our method, and our method performs comparably to or even better than existing supervised and weakly supervised methods, specifically obtaining a frame-level AUC 94.83% on ShanghaiTech.
论文链接:https://arxiv.org/abs/2104.01633
报告11. Deep Optimized Priors for 3D Shape Modeling and Reconstruction
摘要:Many learning-based approaches have difficulty scaling to unseen data, as the generality of its learned prior is limited to the scale and variations of the training samples. This holds particularly true with 3D learning tasks, given the sparsity of 3D datasets available. We introduce a new learning framework for 3D modeling and reconstruction that greatly improves the generalization ability of a deep generator. Our approach strives to connect the good ends of both learning-based and optimization-based methods. In particular, unlike the common practice that fixes the pre-trained priors at test time, we propose to further optimize the learned prior and latent code according to the input physical measurements after the training. We show that the proposed strategy effectively breaks the barriers constrained by the pre-trained priors and could lead to high-quality adaptation to unseen data. We realize our framework using the implicit surface representation and validate the efficacy of our approach in a variety of challenging tasks that take highly sparse or collapsed observations as input. Experimental results show that our approach compares favorably with the state-of-the-art methods in terms of both generality and accuracy.
论文链接:https://arxiv.org/abs/2012.07241
代码链接:https://nicoleyang61.github.io/Deep-Optimized-Priors/
报告12. Self-attention based Text Knowledge Mining for Text Detection
摘要:Pre-trained models play an important role in deep learning based text detectors. However, most methods ignore the gap between natural images and scene text images and directly apply ImageNet for pre-training. To address such a problem, some of them firstly pre-train the model using a large amount of synthetic data and then fine-tune it on target datasets, which is task-specific and has limited generalization capability. In this paper, we focus on providing general pre-trained models for text detectors. Considering the importance of exploring text contents for text detection, we propose STKM (Self-attention based Text Knowledge Mining), which consists of a CNN Encoder and a Self-attention Decoder, to learn general prior knowledge for text detection from SynthText. Given only image level text labels, Self-attention Decoder directly decodes features extracted from CNN Encoder to texts without requirement of detection, which guides the CNN backbone to explicitly learn discriminative semantic representations ignored by previous approaches. After that, the text knowledge learned by the backbone can be transferred to various text detectors to significantly improve their detection performance (e.g., 5.89% higher F-measure for EAST on ICDAR15 dataset) without bells and whistles.
代码链接:https://github.com/CVI-SZU/STKM
报告13. Fourier Contour Embedding for Arbitrary-Shaped Text Detection
摘要:One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.
论文链接:https://arxiv.org/abs/2104.10442
代码链接:https://github.com/open-mmlab/mmocr (即将于mmocr开源)
